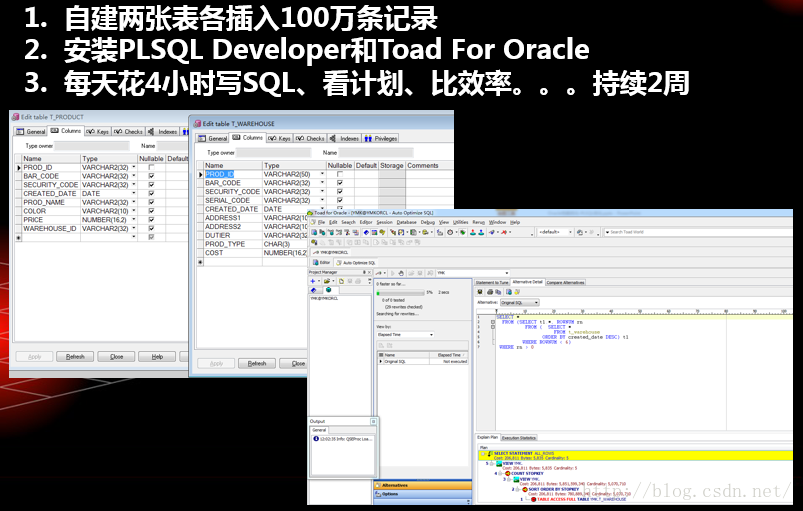
本文共 3051 字,大约阅读时间需要 10 分钟。
60-80% of database performance issues are related to poorly performing SQL,60-80%的数据库性能问题要归结于生产中糟糕的SQL语句!
以此一文来总结笔者近10多年来的工作经验并基于最基本的也是最有效的对于Oracle数据库中的RBO、CBO、索引、WHERE条件进行讲解同时配以大量案例来帮助读者从此文中学到的相关的理论知识快速的运用到其正在从事的生产环境中的优化过程中去。
优化的理论基础

通过Select Count(?)进入优化之旅
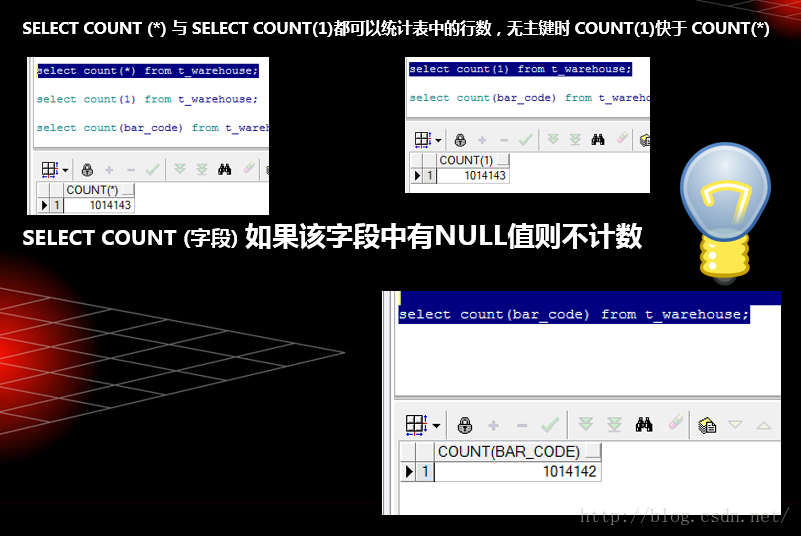
不看百度或者GOOGLE说出下面3者的区别?
SELECT COUNT (*)
SELECT COUNT(1)SELECT COUNT(字段名)SELECT Count(?)的知识
ORACLE的优化器
要说PLSQL优化,我们先需要来好好说一下Oracle优化器的知识:

优化器的优化模式
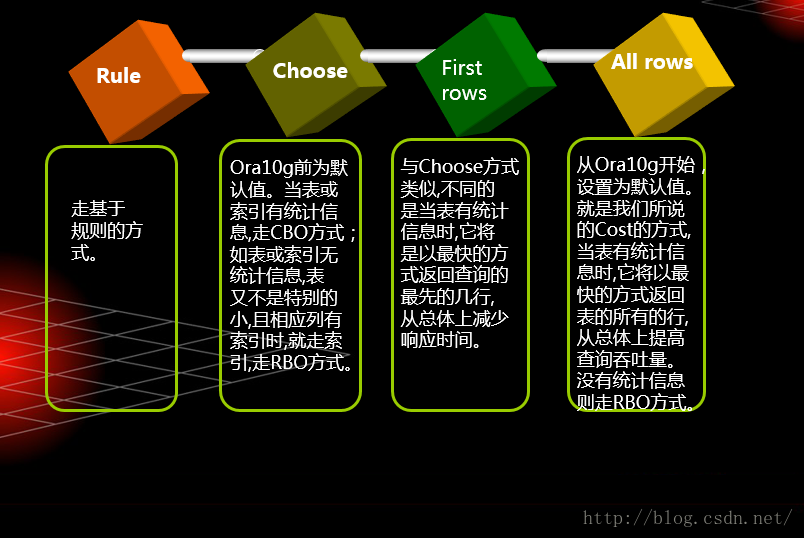
CBO模式

RBO模式

一起来看看oracle优化器的发展历程

所以,我们知道ORACLE10后开始默认使用CBO,在CBO时ORACLE会自动来选择最优的执行计划,有时我们会认为:这个应该走索引更好啊,但是对于CBO来说,一个FULL TABLE ACCESS反而比索引更有效。
因此,在CBO的模式下,我们需要做的就是:
- 做好数据库信息的相关统计
- 合理建设我们的索引
- 优化我们的SQL
让我们从索引的基本知识下手吧
索引按内部结构分类
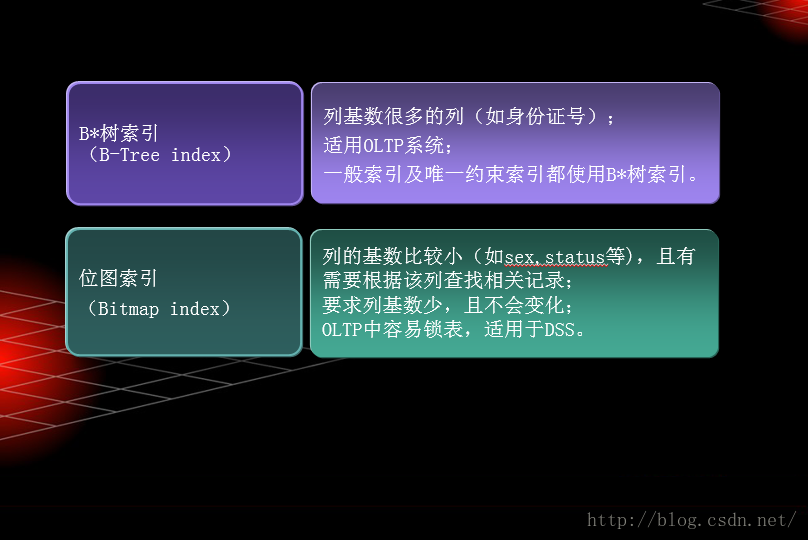
索引按功能分类
索引按索引对象分类

建立索引的方法论
上面介绍了这么多索引的分类,下面来讲讲建立索引的方法论吧,大家可能较关心这个,因为这个是经验总结也是实战有用的利器哈。


不建议建立索引的情况
索引很神奇,可是索引不是万能,有时你建了索引也等于没用或者是白建、作无用功,为什么呢?我们看下去。


索引不会生效的情况
所以索引不要乱建,有时建了也是白建,为什么呢?来看看下面的案例分析吧:

以案例来说明
PLSQL优化>一个不走索引的优化案例
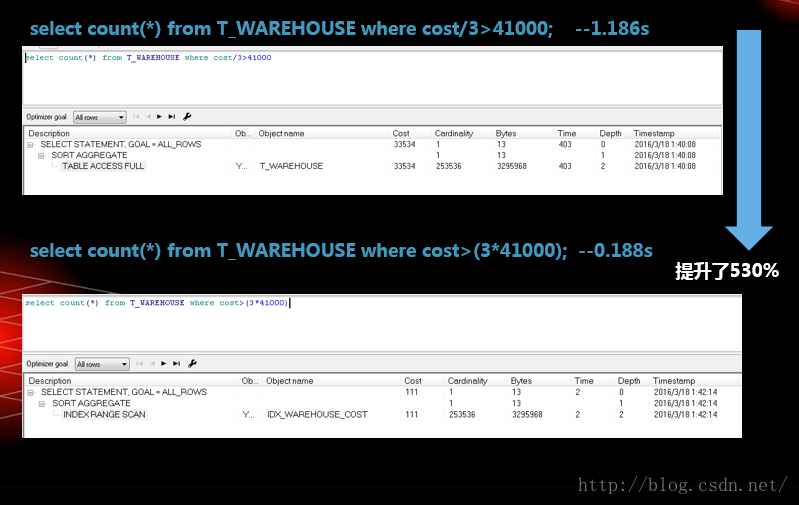
这个例子说明了,如果你有一字参于WHERE条件查询的字段,但是它参于了运算符,因此它在ORACLE的内部执行计划中是不会走索引的,因此我们做了一个小小的变化,效率提升了多少倍?5.3倍,530%,呵呵!
以上例我们可以为建立索引作一个总结。
建立索引的总结

Table Analyze

Analyze Table VS DBMS_STATS

Import & Export
说到Import & Export命令,大家会说。。。哎,这个不是很简单,就是:imp username/pwd@oraid file=path 吗?嘿嘿。。。试想:
- 你需要导入一个8GB左右的.dmp文件进入数据库
- 你需要将一个库,其中含有至少30张表并且每张表都超过1200万条记录的数据进入一个.dmp文件
Import的常规做法

- 第一条,只导数据,不导索引,并且设置成10000条数据一次commit,同时设置了一个缓冲池
- 第二条,只导索引,不导数据,并且设置成10000条数据一次commit,同时设置了一个缓冲池
- 一个含有8GB文件内容的目录,用FTP客户端下载,你会发觉似乎永远等不到头,几小时就这样耗着,然后你改成先把这个目录打成一个压缩包,然后再用FTP客户端 下载,几十分钟就能搞定。
- 你用JDBC写一个FOR循环插入100万条记录。。。结果是ORACLE直接爆掉,而你采用批量提交。。。结果是惊人的!

以案例来说明PLSQL的优化
PLSQL优化-SELECT IN 与SELECT EXISTS
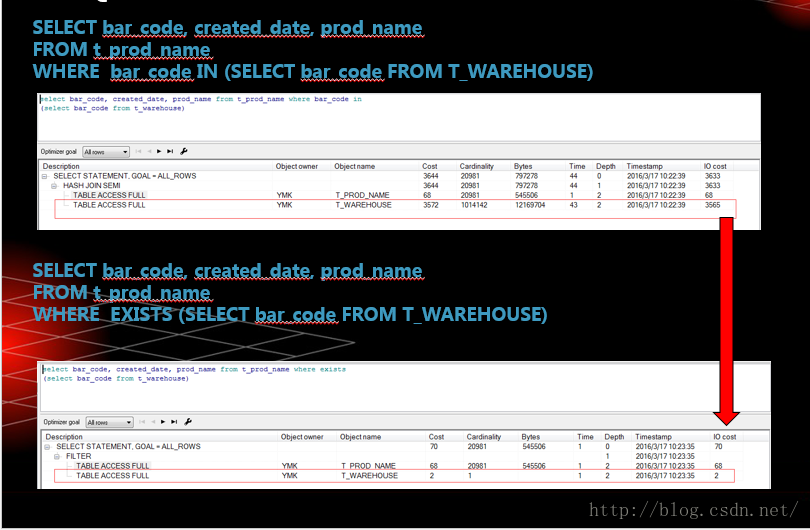
PLSQL优化-SELECT IN的几种优化

PLSQL优化-SELECT IN、OR、UNION的互转

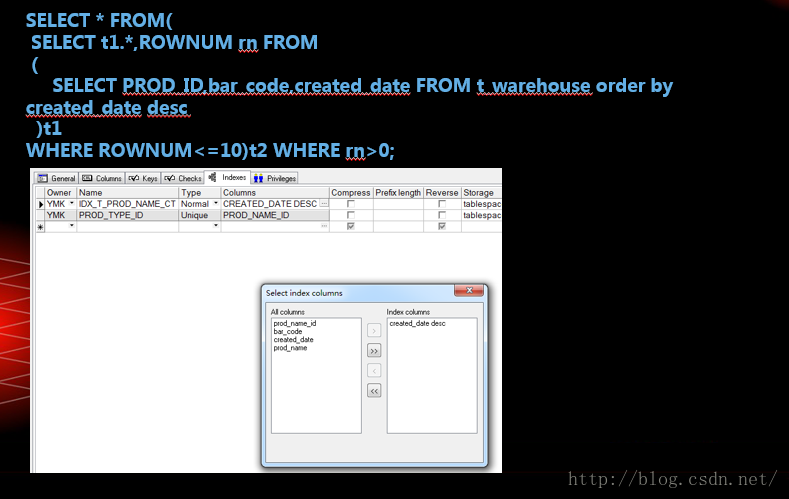
PLSQL优化-分页语句中加入索引的优化
create index IDX_WAREHOUSE_CT on T_WAREHOUSE(CREATED_DATE DESC);
PLSQL优化-INNER JOIN VS WHERE

PLSQL优化-WHERE语句优化要点

WHERE语句中选择最有效的表名顺序


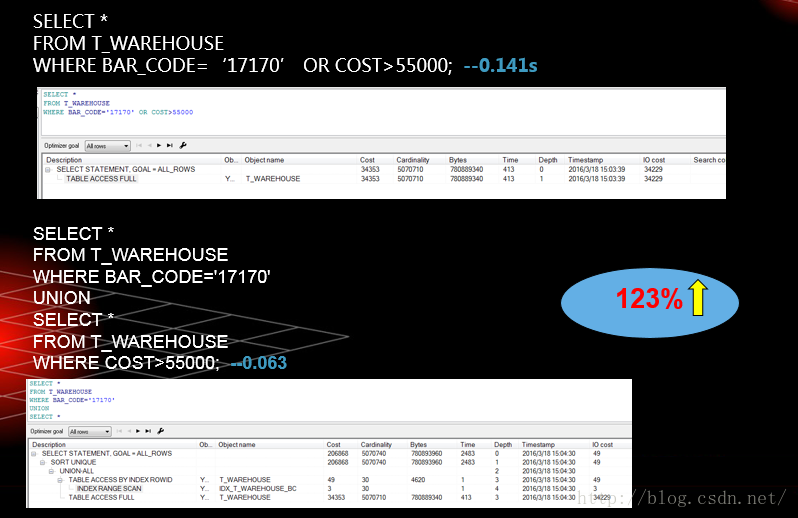
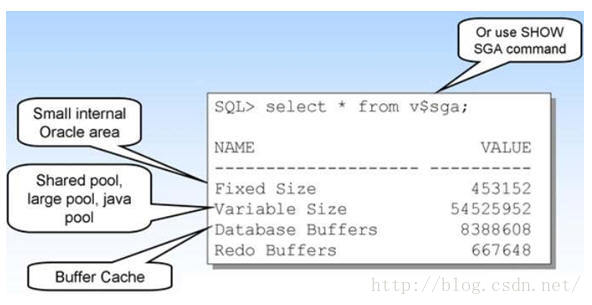
PLSQL优化>共享SQL

如何自学